Arxiv에서 찾을 수 있음.
용어
residual : 나머지
ensemble : 앙상블 (여러 신경망을 사용해 예측을 결합하는 방법)
degradation : 네트워크를 더 깊게 만들었을 때 오히려 성능이 떨어지는 현상
counterpart : 짝
shallow : 얕은
comprehensive : 포괄적인
phenomena : 현상
coarse : adj.거친 adj.해상도가 낮은
asymptotically : adv.점근적으로
문장 “One hypothesizes ~” : ~임을 가정한다면. one은 일반적인 연구자/사람을 가리키는 일반 주어.
precondition : v.어떤 문제를 더 쉽게 풀리도록 변형하거나 조건을 개선하다
perturbations : n.어떤 기준 상태에서의 작은 변화
ResNet
목표로 하는 기초 매핑을 H(x)라고 하면, 쌓인 비선형 층들이 또 다른 매핑 F(x) := H(x) - x를 학습하도록 한다. 그러면 원래의 매핑은 F(x) + x의 형태로 재구성된다.
만약 최적 해가 identity에 가깝다면, 전체 함수를 새로 배우는것보다 조금 수정된 값(잔차) 만 배우는 것이 더 쉽다.
만약 여러 겹의 비선형 층이 점근적으로 복잡한 함수를 향해 수렴할 수 있다고 가정한다면, 이 가정은 여러 겹의 비선형 층은 점근적으로 잔차함수()에 수렴할 수 있다고 가정하는것이다(입력, 출력은 같은 차원이라고 가정한다). 신경망이 에 근사하도록 하는 대신에, 명시적으로 신경망이 잔차함수에 수렴하도록 설정한다. 원래의 함수는 가 된다. 비록 두가지 형태가 모두 점근적으로는 목표로 하는 함수에 수렴할 수 있다고 하더라도, 학습의 난이도는 다를 수 있다.
이 아이디어에 대한 연구자들의 시작은 degradation이라는 비직관적인 현상에 대한 고찰으로, 기존의 신경망에서는 솔버가 Identity Mapping을 만들기 힘들다는 것이었지만, 현실에서는 Identity Mapping이 최적인 경우는 별로 없지만, 이러한 변형(잔차함수 학습)은 문제의 조건을 개선할 수 있다. 만약 최적해가 Zero-Mapping 보다 Identity Mapping에 더 가깝다면, 솔버는 완전히 새로운 함수를 학습하는 것보다 항등 매핑을 기준으로 한 작은 차이가 있는 해를 찾는게 더 쉬울 것이다.
Identity Mapping by Shortcuts
ResNet의 기본 구성 블록(Residual Block)은 아래와 같이 정의된다.
와 는 레이어의 입력, 출력 벡터이다.
함수 는 학습시킬 잔차매핑을 의미한다.
이러한 Shortcut Connection은 추가적인 파라미터나 계산 복잡성을 추가하지 않는다.
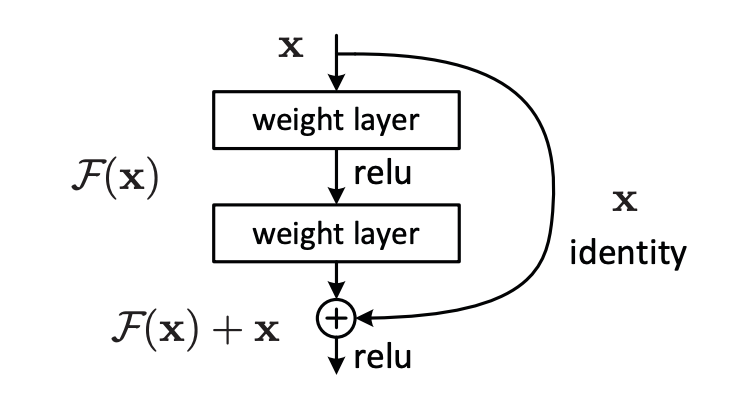
위의 그림은 으로 표현될 수 있으며, 여기서 는 ReLU를 뜻한다. bias는 표현의 간략화를 위해 생략되었다. 연산 은 Shortcut Connection에 의해 수행되었으며 이는 element-wise(요소별) 더하기이다.
식 에서 와 는 같은 차원이어야 한다. 만약 그렇지 않다면, 차원을 맞추기 위해 선형 투사 를 수행할 수 있다.
차원을 변형시키기 위함이 아니더라도 Squart Matrix 를 적용할 수도 있지만, degradation문제를 해결함에 있어서는 identity mapping으로 충분하다.
잔차함수 의 형태는 자유롭다. 두, 세 레이어를 표현할 수도 있고, 가능한 경우 더 많이 포함할 수도 있다. 그러나 만약 가 단 한 개의 레이어를 가지고 있다면, 식은 인 선형층과 매우 비슷해진다. 이러한 형태에서는 어떠한 장점도 찾을 수 없다. 1
CNN에서의 ResNet
위의 표현은 간단함을 위해 fc를 사용하였지만, 합성곱 층에도 적용될 수 있다. 함수 는 다층의 합성곱 층을 표현할 수 있다. CNN에 ResNet을 적용하기 위해서는, 두 특성 맵에, 채널끼리, 원소별 합을 취하게 된다. 2
왜 잔차학습을 하면 Identity Mapping으로 수렴하기 쉬운가?
만약 최적해가 라면, 비선형 변환을 여려번 거쳐서 최적해에 도달하기 어려움은 경험적으로 알 수 있다. (증명이 존재하는지는 모르겠지만 수학적 직관에 의하여 거의 확실하다)
잔차 표현에서는 이므로 을 만들면 되니까, 가중치만 0으로 수렴시키면 되기 때문에, 훨씬 쉽다. 덧셈 이후에 두 번째 비선형 함수(ReLU)를 적용한다.
Network Architectures
저자는 설명을 위해, ImageNet을 위한 두가지 모델을 제시한다.
Plain Network
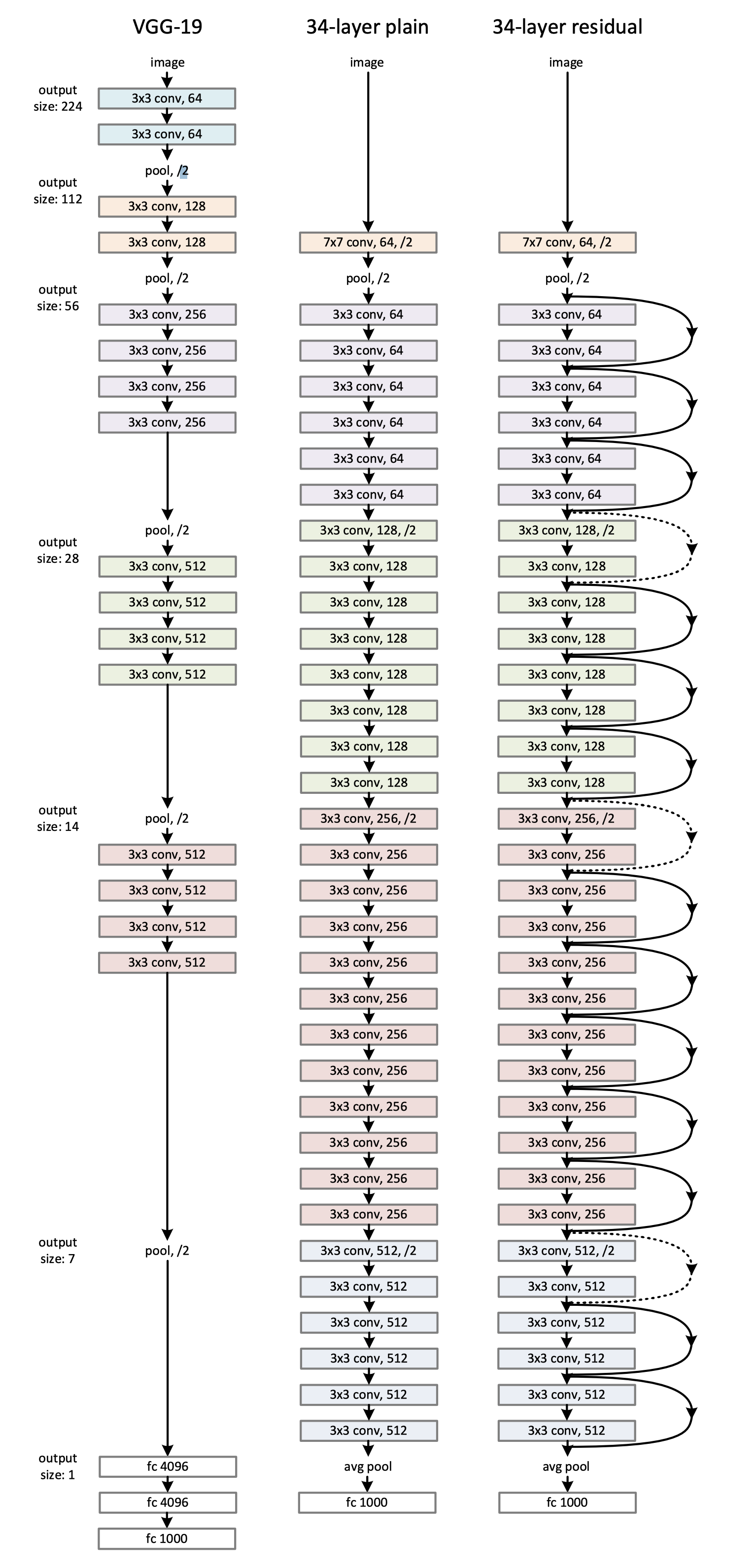
사진3의 가운데 모델. VGG넷의 철학에서 영감을 받았다.
대부분의 합성곱 필터는 3x3의 크기이고 다음과 같은 간단한 규칙으로 설계되었다.
{kind=link}
- 출력 특성 맵의 같은 크기를 위하여, 레이어는 같은 수의 필터를 가진다.
- 만약 특성 맵의 크기가 반으로 줄었다면, 필터의 크기는 두 배로 설정한다. (그렇게 하여 레이어당 복잡도를 유지시킨다)
다운샘플링은 스트라이드가 2인 합성곱 계층을 사용하여 직접 수행한다. (특징 맵의 크기를 줄이는 작업은 별도의 풀링연산 없이 이러한 과정으로 수행한다)
네트워크는 global average pooling layer와 1000-way Softmax FC레이어로 마무리된다. 4
그림에서, 가중치 레이어의 최종 개수는 34개이다.
우리의 모델은 VGG넷(그림의 왼쪽)보다 필터의 수는 적고, 복잡성도 낮다. 우리의 34레이어의 기본모델은 3.8B FLOPs이고, 이는 VGG-19의 18%이다.
Shortcut Connections
하나 또는 그 이상의 레이어를 건너뛴다.
Identithy Shortcut Connection은 추가적인 파라미터나, 복잡한 계산을 추가하지 않는다.
숏컷 커넥션을 추가해도 전체 네트워크는 end-to-end로 SGD 역전파를 통해 훈련될 수 있다.
저자가 ImageNet실험으로 보인 것
- 매우 깊은 ResNet은 학습시키기 쉽다. 하지만 일반적인 신경망은 깊이가 증가할수록 높은 Training Error를 보이게 된다.
해석 못하는 문장
Abstract
1
We explicitly refomulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions
reference : v.참조하다
우리는 명시적으로 재구성합니다 / 각 층이 [각 층의 입력을 기준으로 한] 잔여함수(residual function)을 학습하도록 / 입력을 참조하지 않는 일반적인 함수 (를 학습) 대신에
2
We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth
comprehensive : adj.포괄적인
emprical : adj.경험적인
우리는 포괄적이며 경험적인 증거를 제공합니다 / (그 증거는) residual networks는 최적화하기 쉬우며, 정확성을 얻을 수 있습니다 / 상당히 증가시킨 깊이로부터
3
Soley due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset.
soley : adv.단지 그것만으로
오직 우리가 사용한 매우 깊은 표현 때문에, 우리는 28%상대적인 개선을 이뤘습니다. COCO 객체인식 데이터셋에서
4
Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
Deep residual 신경망은 기초입니다 / 우리의 ILSVRC & COCO 2015경쟁의 출품작의 / (그 경쟁은) 우리가 또한 ImageNet detection, ImageNet localization, COCO detection, 그리고 COCO segmentation에서 1위를 차지한
1. Introduction
1
Deep networks naturally integrate low/mid/high-level features and classifiers in an end-to-end multi-layer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth).
integrate : v.통합하다
fashion : n.방식
깊은 신경망은 자연스럽게 통합한다 / 낮은,중간,높은 수준의 특징과 분류기를 / End-to-End 다층 구조 안에서 / 그리고 특징의 “수준”은 풍부하 질 수 있다 / 쌓여진 층에 수에 의하여
2
Recent evidence reveals that network depth is of crucial importance, and the laeding results on the challenging ImageNet dataset all exploit “very deep” models, with a depth of sixteen to thirty.
exploit : v.적극적으로 이용하다
최근의 증거는 밝혀낸다 / 망의 깊이가 최고로 중요함을 / 도적적인 ImageNet 데이터셋의 최상위 결과들은 모두 적극적으로 이용한다 / 매우 깊은 모델을 / 깊이가 16에서 30까지인
3
An obstacle to answering this question was the notorious problem of vanishing/exploding gradients, which hamper convergence from the beginning.
hamper : v.방해하다
convergence : n.수렴
이러한 문제의 대답에 대한 장애물은 / 기울기소실,폭발의 악명높은 문제였습니다 / (그 기울기 소실,폭발은) 처음부터 수렴을 방해합니다.
//여기서 수렴은 모델이 기울기를 찾아가는 과정을 뜻함
4
This problem, however, has been largely addressed by normalized initialization and intermediate normalization layers, which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation.
address : v. 대응하다 v.해결하다(완전히는 아님)
하지만, 이 문제는 크게 해결되어 왔습니다 / 정규화된 초기화 기법과 중간 정규화 계층에 의해 / (정규화된 초기화 기법과 중간 정규화 계층은) 수십 층 규모의 신경망을 수렴하도록 만들기 시작했다 / SGD 역전파로 인하여
5
There exists a solution by construction to deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart.
by construction : 구성적으로
구성적으로 하나의 해가 존재한다 / 깊은 모델에 대해서 / (그 해는 다음과 같음) 추가된 레이어는 Identity Mapping이고, 나머지 레이어는 학습된 얇은 모델을 복사한 것
이러한 구성된 해가 존재함은 시사한다 / 깊은 모델은 반드시 생산하여야 한다 / 높지 않은 훈련오차를 / 이것의 얕은 짝보다
6
Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks.
substantially : adv.크게
우리의 “깊은 잔차 네트워크” 쉽게 정확도를 향상시킬 수 있습니다 / 크게 깊이를 증가시킴으로써 / 기존 네트워크보다 훨씬 좋은 결과를 나타내면서
7
Similar phenomena are also shown on the CIFAR-10 set, suggesting that the optimization difficulties and the effects of our method are not just akin to a particular dataset
akin : 국한되다..?? 아무튼 여기서는 그런 뜻으로 쓰였다.
비슷한 현상이 보여집니다 / CIFAR-10 세트에서도 / 이는 보여준다 / 학습 난이도와 우리의 방법의 효과는 / 특정 데이터셋에만 국한된것이 아님을
8
We present successfully trained models on this dataset with over 100 layers, and explore models with over 1000 layers.
우리는 성공적으로 보여줬습니다 / 이 데이터셋에서 (성공적으로) 학습시킨 모델을 / 100층이 넘는 모델 / 그리고 1000층이 넘는 모델까지도 탐구하였습니다.
Footnotes
-
근데 레이어가 문제가 아니라 활성화 함수어디에 끼워넣나에 따라 다르지 않을까? 어쨌든, 논문에서는 그냥 단순한 선형 레이어 하나인 경우라고 이해하면 될듯함 ↩
-
그러니까 하나는 특성 맵이고, 하나는 입력을 그대로 가져오는데 차원이 다르니까 선형 투사를 적용해야 한다는 뜻인듯 ↩
-
그림에 7x7 conv, 64, /2 라는 표현이 있다.
읽는 방법은 7x7 : 커널의 크기가 7x7
64 : 출력 채널 수(필터 개수)
/2 : 스트라이드 = 2 ↩ -
컨볼루션 레이어를 타다가 결국 3x3특성맵이 512채널을 가지게 된다.
그러고 global average pooling하여 채널마다 하나의 값이 남는다.
그 후 이 512차원 벡터는 1000개의 출력 뉴런에 Fully Connected된다. ↩