개요
훈련 데이터를 과하게 학습한 경우
ex) 검은색 강아지에 대해 과적합된경우 흰색 강아지를 강아지가 아니라고 판단.
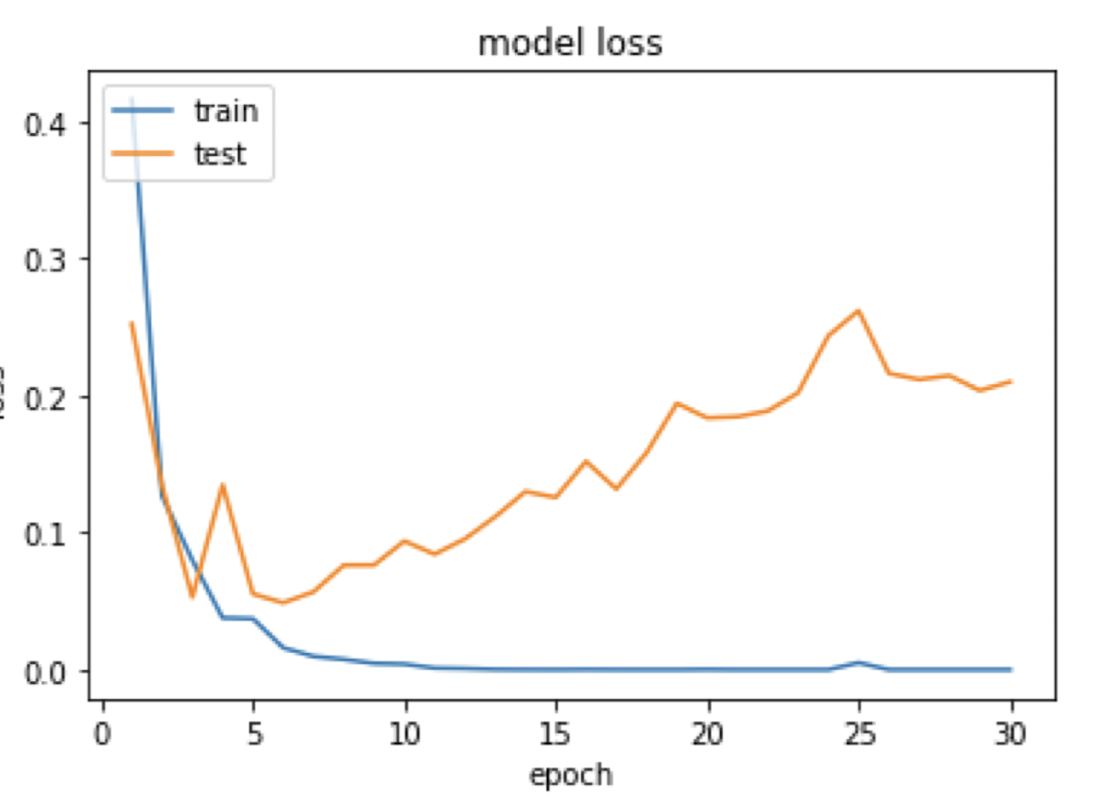
테스트 데이터의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것이 바람직함.
Dropout, Early Stopping 과 같은 과적합을 막을 수 있는 방법이 있음.
Ways to Prevent Overfitting
데이터의 양을 늘리기
데이터의 양이 적을경우 해당 데이터의 특정 패턴이나 노이즈까지 쉬이 학습하게 된다.
모델의 복잡도 줄이기
복잡도 ~ 매개변수, 은닉층
가중치 규제 적용하기
가중치 w의 값 자체를 작게 만들도록 설계
L1 Norm
가중치 w들의 절대값 합계를 비용함수에 추가
하이퍼파라미터 , 기존의 비용함수에 를 더함원본 링크
- 많은 가중치를 0으로 만든다 → 필요없는 특성을 제거
L2 Norm
모든 가중치 w들의 제곱합을 비용함수에 추가
기존의 비용함수 각 가중치항에대하여 를 더한다원본 링크
- 가중치를 0으로 만들지는 않는다
- 부드러운 제약이고, 안정적이다.
이게 보통 많이 쓰이는 정규화이다.
optim.Adam()에 weight decay값을 주면 L2정규화 효과를 낸다.
Dropout
학습 과정에서 신경망의 일부를 사용하지 않는다.
ex) 드롭아웃의 비율이 0.5라면 학습 과정마다 랜덤으로 절반의 뉴런만 사용한다
드롭아웃은 신경망 학습 시에만 사용하고, 예측시에는 사용하지 않는것이 일반적.
앙상블 효과와 유사한 결과를 낸다.
원본 링크
(매 학습마다 서로 다른 서브네트워크를 학습시키기 때문에)